aide demandée fréquences d'échantillonnage, resampling et résolution démystifées ?
- 104 réponses
- 18 participants
- 15 183 vues
- 27 followers
Brubao

J'ai passé du temps à faire des tests et à réfléchir pour essayer de déterminer le format audio optimum pour l'enregistrement et le travail en studio.
Au final je me pose encore quelques questions, auxquelles peut-être des spécialistes pourront répondre de façon éclairée ? (je les ai mises en gras)
Voici d'abord quelques réflexions suite à mes observations.
Vu que c'est un chouilla long
Fréquence d'échantillonnage :
1) première approche :
il paraît évident dans l'absolu qu'un signal échantilloné à une fréquence élevée sera plus proche du signal analogique original (continu).
Au-delà de la bande passante et du théorème de Shanon Nyquist (qui sert un peu vite d'argument à tous les partis), le rendu des aigus en particulier devrait être plus juste, moins distortionné (décrire une sinusoïde avec 2 points ça paraît pas top).
Evidement on pourrait répondre que les fréquences en question sont inaudibles pour nos vieilles oreilles et que la distorsion des aigues ne fera que créer des harmoniques encore plus aigus et inaudibles (et qui seront de toute façon filtrés dans les formats audio de consommation actuels, fort heureusement dirait Nyquist).
Au final, est-ce que ça fait réellement une différence (surtout pour de la musique consommée en 44.1 kHz) ?
2) traitements et sommation :
en cas de mixage numérique, je suppose que les plugins peuvent délivrer un résultat sonore plus proche de l'analogique s'ils traitent un son "plus continu". En tous cas la différence m'a semblée flagrante à l'audition sur des réverbs qui prenaient une toute autre dimension et consistance (comparaison projet test en 44.1 et en 192).
Au delà du point de vue spectral, je suppose qu'une F.d'E. plus élevée amène une meilleure fluidité temporelle et dynamique.
La sommation aussi est meilleure je suppose, vu la résolution temporelle accrue et la plus grande précision des valeurs à sommer (erreurs de crête moindres, représentation des niveaux plus fidèle à chaque échantillon).
3) rendu final (44.1 kHz) :
Pour me rendre compte si au final ça faisait une différence de travailler à des F.d'E. supérieures, j'ai fait ce test :
- j'avais un projet enregistré en 44.1 kHz.
- j'ai resamplé toutes les pistes en 192 kHz (crystal resampler, wavelab 7).
- j'ai mixé en 192 kHz.
- exporté en 192 kHz puis resamplé en 44.1 kHz.
- j'ai dupliqué le projet de mixage en 44.1 kHz et passé les fichier originaux dedans.
- j'ai créé un fichier delta (différence entre les deux exports finaux).
Conclusions :
- à l'écoute il me semble entendre une différence entre l'export 192 et l'export 44.1 (plus d'ampleur, d'ouverture).
- par contre entre l'export travaillé en 192 puis resamplé en 44 et l'export tout 44, c'est moins évident (difficile de jurer que la différence n'est pas suggérée).
- Evidement, je ne saurai jamais si j'aurais mixé de la même façon en 44 qu'en 192 (ça m'a quand même paru auditivement très confortable, impression d'entendre plus clairement ce qu'il y avait à faire et ce que je faisais).
- le fichier delta montre une différence objective tout à fait flagrante entre les 2 exports (travaillés en 192 puis resamplé en 44 contre tout 44). On a l'impression d'entendre la composante "définiton" du son. Mais je me demande si elle n'est pas liée au resampling à des fréquences non multiples (parce qu'en écoute comparative c'est loin d'être aussi flagrant).
Du coup, vu que j'étais lancé, j'ai resamplé mes fichiers en 174.6 kHz, je les ai repassés dans le mix version 174, puis j'ai exporté et resamplé en 44.1.
Effectivement, le fichier delta est beaucoup moins flagrant même s'il reste une différence du même genre que l'autre fichier delta.
A part ça, les conclusions sont du même ordre qu'avec le mix en 192.
Plein de motivation, j'ai reproduit les processus en 88.1 kHz. Comme on pouvait s'y attendre, les constats sont du même acabit mais moins prononcés.
Il y a quand même quelque chose qui me turlupine :
La comparaison entre le mix en 44 et en 192 (fréquences non multiples) sous forme de fichier delta fait ressortir un résidu très estéthique (sorte de composante de définition du son).
C'est manifestement lié au resampling à des fréquences non multiples : j'ai fait le test de resampler un fichier 44.1 en 192 puis de nouveau en 44.1 et de comparer avec l'original. La différence est du même type.
Les questions que je me pose (même si la différence semble moins flagrante en écoute comparative) :
- est-ce dû à un phénomène de "déphasage d'échantillonnage" qui ferait entendre une différence flagrante mais non pertinente (de la même façon qu'on pourrait obtenir un effet de filtre en peigne flagrant en comparant 2 fichiers très légèrement décalés) ?
- si ce n'était pas le cas, serait-il possible qu'un resampler de bonne qualité, "obligé" d'extrapoler la courbe continue d'une façon plus approfondie pour des fréquences non multiples, offre au final un meilleur résultat ?
4) questions en suspens :
- fréquences multiples ou pas ?
pour les multiples :
. ça paraît plausible que la reconversion soit plus simple en cas de fréquences multiples et amène moins d'artéfacts...
. pourquoi les constructeurs s'emmerderaient sinon à proposer 88.2 et 176.4 kHz ?
pour les non multiples :
. dans l'absolu, avec une fréquence d'échantillonnage plus élevée on se rapproche davantage de ce cher son continu.
. la différence absolue du nombre d'échantillons devient peut-être intéressante aux ordes supérieurs de fréquence d'échantillonnage ?
. avec de bons convertisseurs ou en cas de mastering analogique par exemple, l'histoire de fréquences multiples devient peut-être moins pertinente ?
- 44/48, 88/96 ou 174/192 ?
. par rapport au rendu sonore final, à quel point est-ce que ça vaut la peine de mutliplier la F.d'E. (vu que les ressources nécessaires doublent chaque fois) ? Concrètement, est-ce que ça vaut pas la peine ? x2 ? x4 ?
. le son qu'on entend est quand même toujours reconverti en analogique, passé dans des haut-parleurs avec une inertie non nulle, propagé dans un air élastique et capté par nos oreilles au fonctionnement continu.
Au mieux tous ces éléments sont de très bonne qualité. Dans ce cas les convertisseurs lisseront joliment le signal, les haut-parleurs rendront fidèlement ce signal joliment analogisé, l'air sera transparent (si j'ose dire
Ou alors les convertisseurs lissent mal le signal sonore, les caractéristiques des HPs se combinent justement très mal avec ces irrégularités (tweeter hyper agressif), l'air déforme le son en le propageant avec un mauvais goût total, les oreilles qui perçoivent le résultat sont abîmées et la personne à qui appartiennent ces oreilles ne cherche pas à apprécier les jolies subtilités (ça tombe bien).
Dans l'immense majorité des cas, la réalité se situe quelque part entre ces 2 extrêmes (toutes les combinaisons d'incidence étant possibles).
Mais honnêtement, dans quels cas le fait de travailler à des F.d'E. supérieures à 44.1 kHz aboutira à une différence pertinente pour l'auditeur ?
Résolution :
1) 16 bit :
Si je ne me trompe pas, il y a 1 bit de signe (pour la polarité), il reste donc 15 bits pour décrire l'amplitude du signal, soit 2^15 = 32768 valeurs pour décrire le niveau de l'échantillon.
Pour une plage dynamique de 90 dB, ça ferait donc 364 valeurs possibles par dB...
Si c'est bien juste, ça me paraît déjà franchement bien !
2) 24 bit :
Les 8 bits supplémentaire ne servent qu'à décrire les niveaux inférieurs à - 90dB. C'est d'ailleurs confirmé avec un bitmètre.
Franchement, est-ce que ça change quelque chose ?
Je veux bien croire que ce n'est pas purement marketing, mais j'ai du mal à comprendre où est la pluvalue, que ce soit à l'enregistrement, pour les traitements ou la sommation : même pour de la musique classique ou un instrument seul très léger et plein de transitoires et d'harmoniques, j'ai l'impression que c'est quand même rare d'avoir un passage musical qui module suffisament bas pour que ce qui se passe quelque part à -90dB ne soit pas masqué par d'autres composantes sonores ou simplement par le bruit de fond environnant à l'écoute (ampli et HP compris).
3) 32 bit flottant :
Grâce à la virgule flottante on peut décrire à travers toute la plage dynamique des niveaux intermédaires qui ne sont pas utilisés en virgule fixe. Dès lors la pluvalue semble plus claire (enregistrement, traitements, sommation).
Sauf que si mes calculs sont justes (quelqu'un peut-il confirmer ?), même en 16 bit on a 364 valeurs par dB cf. § 16 bit).
Si c'est bien le cas, est-ce vraiment utile d'en avoir plus (même pour la sommation de nombreuses pistes), vu qu'on travaille au mieux au 1/10 de dB ?
Si je calcule bien (mais je me trompe peut-être), on obtiendrait une différence d'1/10 de dB entre une résolution à virgule fixe ou flottante si on avait par exemple à sommer 73 signaux tous très mal approximés par la virgule fixe.
Calcul : en virgule fixe 364 valeurs par dB -> erreur d'approximation maximale = moitié de cet intervalle (donc 1/728ème de dB) -> il faudrait donc cumuler 72,8 erreurs pour atteindre 1/10 de dB...
Et en plus, en cas de travail en virgule flottante, au final les valeurs sont de toute façon arrondies. Donc même si les valeurs finales sont légèrement plus justes après traitements et sommation que si on était resté en virugle fixe, cette précision est quand même partiellement rabotée (et là, même débat que pour les fréquences d'échantillonnage supérieures).
4) en conclusion :
Je veux bien croire qu'il y ait une bonne raison pour que les constructeurs et développeurs proposent des produits qui travaillent en 24 bit, 32 bit flottant, 48 bit non flottant... mais quelle est-elle ?
Quelqu'un d'avisé peut-il expliquer clairement si ça vaut la peine d'enregistrer et/ou de travailler en plus que 16 bit et à quel point ça fera une différence ou pas ?
Si vous avez tout lu, waw !
Si vous avez parcouru et relevé certaines questions, super !
Si vous pouvez y répondre de façon éclairante et justifiée, MERCI !!
69000

À-t'on une bonne base si on enregistre des synthés en 24/96 puis on les bosse en 32float/96 dans wavelab pour finir par faire un export en dithering interne?
Danguit

Si un effet produit de l'intermodulation c'est parce-que c'est ce qu'on lui demande. Elle intervient pas par magie.
Plus sérieusement, tout système dans ses zones de non-linéarité génère des produits de mélange lorsqu'il est attaqué par plusieurs signaux, et cela s'appelle de l'intermodulation.
guitoo

Pour travailler une piste dans un éditeur audio externe c'est bien de l'exporter en 32 bits plutôt qu'en virgule fixe. Ca permet de travailler au volume définie par le fader de la piste tout en autorisant de remonter le volume plus tard si on le souhaite.
En numérique une transformation linéaire est linéaire point. Une transformation non linéaire produit de l'intermodulation par définition.
Si l'intermodulation produit des fréquence au delà de Fe/2 c'est de l'aliasing et on est dans le sujet du débat. Sinon c'est un fonctionnement tout à fait normal.
Si l'auteur du plugin souhaite réaliser un effet linéaire mais qu'il ne l'est pas c'est un autre problème et c'est pas le débat ici.
69000
Bonne journée à vous tous!
Danguit
EraTom

C'est seulement partiellement vrai. Un modèle de filtre en continu et son équivalent en discret n'ont pas exactement la même réponse en fréquence. De même 2 filtres discrets définis pour des Fe différentes auront des réponses en fréquences légèrement différentes. un filtre continu est une fonction du spectre sur ]0;+inf[ or un filtre numérique est une fonction du spectre périodique et symétrique de période Fe. En mappant la demi droite ]0;+inf] sur un cercle on distord la réponse en fréquence aux extrémités 0 et Fe/2. Le filtre continu lui n'est pas nécessairement symétrique autour de Fe/2 et 0.
Si tu as une chaîne :
"filtre fréquentiel => filtre passe-bas (antialiasing) => décimation"
il est tout à fait possible de construire une chaîne :
"filtre passe-bas (antialiasing) => décimation => filtre fréquentiel"
Bien sûr, les filtres fréquentiels numériques n'auront pas les mêmes coeff puiqu'ils travaillent à des fréquences différentes, mais il est possible d'obtenir la même sortie finale.
Dans le cas d'un FIR, tu peux designer les filtres de façon à ce qu'ils reproduisent exactement la même sortie et en plus tu gagnes du temps de calcul.
Pour les IIR, s'ils possèdent un étage de correction de phase (pour la rendre la plus linéaire possible dans la bande utile)... L'intérêt de sur-échantillonner au mixage est vraiment limité (ils se comportent quasiment comme des FIR).
Tu évoques le warping qui intervient avec la transformée bilinéaire pour la synthèse de filtre numérique à partir de filtres continus ?
Effectivement, mathématiquement sur-échantillonner peut repousser le problème, mais le gain est quand-même à relativiser si l'on n'oublie pas quelques données psycho-acoustiques (la largeur de la bande critique à 15kHz fait 3.5kHz)
https://ccrma.stanford.edu/~jos/sasp/Bilinear_Frequency_Warping_Audio_Spectrum.html
Une saturation naïve produite par écretage va produire des fréquence au de la de Fe/2 et par symétrie on retrouve ces fréquences sous Fe/2. Il existe très probablement des méthodes moins naïves pour limiter ce phénomène mais on ne peut pas sans débarrasser complètement sans suréchentillonage (qui se produit au sein du plugin lui même, pas besoin de monter la fréquence d’échantillonnage).
Je pensais aux effets "lo-fi" dont certaines proposent justement de jouer sur l'aliasing.
Pour une saturation plus "classique" on peut supposer (comme tu le fais justement remarquer) que le recouvrement est géré convenablement.
Mon propos est que travailler à une fréquence d'échantillonnage (au mixage) plus élevée pour récupérer des harmoniques HF qui seront de toutes façon éliminées lors du sous-échantillonnage final ne me semble pas très pertinent (doux euphémisme).
Je ne vois pas très bien ce que tu entend pas déplacement du spectre vers le bas.
Une modélisation physique d'une reverb peut produire des basses fréquences à partir d'excitation hautes fréquences (je pense notamment à un phonon absorbé par un "mur" et réémit à une fréquences plus basse, comme pour un corps noir en thermo).
Mais je ne pense pas que ce genre de modèle soit sorti des labo pour se retrouver dans les studio. Je me trompe ?
Si je me trompe et si en entrée tu présentes un signal avec une bande 0-44kHz, tu pourrais bien récupérer quelque chose de plus à la sortie de la reverb dans la bande 0-22kHz que tu souhaites conserver. Mais encore une fois, est-ce qu'un tel niveau de modélisation existe dans un plug ?
avec des temps d'attaque et de release très cour s’apparente a une distorsion
Très courts relativement à quoi ?
philrud
Hors sujet :
De mon côté ,je viens de passer ma soirée à faire les tests sur le numérique dont je rêvais depuis des années,dont j'avais des suspiçions,des doutes .Ca y est ,maintenant j'ai peut-être trouvé la réponse à mes questions.Mais je me pose maintenant d'autres questions ...J'ai quand même du mal à croire ce que j'ai vu;je me dis que c'est pas possible ;j'ai l'impression d'avoir eu "la berlue"(sans plaisanter).Mes tests ont été une comparaison entre un convertisseur à fe=46khz ,un autre à une fe de 96khz et à un appareil analogique.Et plus j'essaie de comprendre,plus j'ai l'impression de plus rien comprendre...
Je trouve ce sujet passionnant :merci à tous et en particulier à EraTom.
Mon soundcloud Good times !
Brubao
Ca me semble lié au sujet, puisqu'apparemment l'inutilité des Fe supérieures à 44,1 kHz est liée aux convertisseurs...
philrud
Citation de Brubao :
En gros c'était quoi les questions que tu te posais et les conclusions de tes tests ?
1/ Questions que je me posais :
Je me posais une très vieille question comme :pourquoi quand j'écoute un vieux disque vinyl ,il y a systématiquement plus de hauteur dans le son ?.Pourquoi on nous vante dans le commerce une fe qui va plus haut en fréquence?Mais qu'est ce qu'il y a d'autre comme différence dont je n'ai jamais entendu parlé ni sur AF ni ailleurs entre diverses fe et l'analogique à l'écoute?
2/Les conclusions de mes tests :
1/Test 1 : sur stéréo ,les 2 convertisseurs delta-sigma 46khz et 96khz ont une perfection totale sur toute la bande passante.L'analogique est très bon ,mais montre des imperfections.
2/Test 2 :sur convertisseurs J'ai découvert une rotation de phase cyclique ,permanente et régulière de 90° qui revient toutes les 40ms sur toute la bande passante ,mais je n'ai mesuré que de 100hz à 20khz.
Ca fait ;imaginons :0° ,après 40ms on a - 90°,puis encore après 40ms on revient à 0°,puis après 40ms on revient à -90°,puis 0° après 40ms ,etc...Ca fait ça sur toute la bande passante .En fait tous les 25hz on a une rotation de phase de 90°.
Ce schéma est exactement le même sur les 2 convertisseurs(46khz et 96khz)=mêmes mesures .
En analogique ,ça le fait pas ,même si ce n'est pas parfait.
Le problème que j'ai ,c'est que j'ai fait des écoutes sur ce type de test et la conclusion était :il faut absolument aucune rotation de phase à ce niveau ,sinon ça sonne moins bien .Et là ou je ne comprends plus rien ,c'est que malgrès cette rotation ,ces convertisseurs sonnent excellement bien (des delta-sigma !)
Je vais finir par perdre la tête...
Mon soundcloud Good times !
philrud
...Finalement ,j'ai continué à chercher ,j'ai fait d'autres mesures =mêmes résultats.Puis je me suis penché sur la théorie ,sur les divers temps transitoires , sur Nyquist et sur ce que peut entendre l'oreille humaine de tout ça...
Voilà le résultat :
Dans mon appareil de mastering ,il y a des dsp et le converto' AN/NA .On sait qu'un signal dans les hautes fréquence peut monter en 16µs dans un converto'AN/NA .Mais on sait qu'il y a le temps de calcul des dsp et aussi le temps de retard que le constructeur a ajouté volontairement afin que l'appareil ait le temps d'analyser le signal pour le corriger (ex: correcteurs automatiques ,anti-larsen ,compresseur etc...) .On sait aussi que plus il y a de mots binaires lourds ,plus le temps transitoire s'allonge.Donc les 40ms que je mesure sont la totalité de tous ces temps.
Autre exemple :un convertisseur AN/NA 12 bits dans les années 80'avait un temps de transfert de 25µs (analog device);on est loin des 40ms mesurés ici.Donc,séparons bien les choses ...
J'en reviens à ma phase et son décalage et d'après moi ,le 0°-90°-0°-90°-0°-90°(etc...) que je mesure est tout simplement dû à la coube non linéaire de Mr Nyquist ;courbe (log ; voire log/anti-log) créée à cause de la (mauvaise) sensibilité de l'oreille humaine sur les bas niveaux .
Bilan :il y a bien une distorsion de phase dans un convertisseur AN/NA de ce type puisque je la mesure .Chose qui n'apparaît pas en analogique "parfait" même si je ne mesure pas le temps de transfert exact du convertisseur.Mais l'oreille humaine est-elle capable d'entendre ce défaut là ?
Pour connaître exactement si ce déphasage est gênant ,il faudrait faire une comparaison en direct :je viens de la faire entre un vinyl et un CD du même titre .Très difficile de dire qui est mieux que l'autre au point de vue phase.C'est (pour moi) le même placement dans la profondeur .
Conclusion :
Mr Nyquist a plus d'un tour dans son sac ,puisque malgrès ce défaut de phase ,il m'est quasi-impossible d'entendre la différence "à l'oreille" et en comparaison directe entre un son avec ce défaut et le même son sans ce défaut temporel.Je dis :"bravo" et merci à des gens comme ça: des génies "en vrai" ! ![]()
----------------------------------------------------
Peut-être quelques photos à venir pour illustrer ...Et qui sait une 3ème conclusion si je découvre plus tard autre chose que je ne vois pas aujourd'hui...
Mon soundcloud Good times !
philrud
Appareil de mastering testé :les croix = traitements DSP mis hors service.

Mon soundcloud Good times !
philrud

philrud
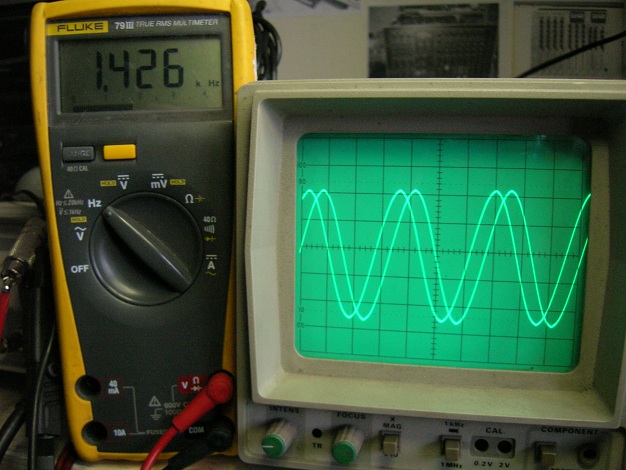
philrud

philrud
Voilà ,dernière photo : ça parle tout seul .J'ai limité le nombre de photo pour pas charger le forum,mais ça fait pareil sur toute la bande 20hz à 21khz .

Mon soundcloud Good times !
guitoo
Si les mises en phase apparaissent périodiquement avec la fréquence, alors c'est le signe d'un délai indépendant de la fréquence. Sinon c'est probablement du a la réponse de phase du low pass en sortie.
philrud
Citation de guitoo :
Tu affiche l'entrée et la sortie?
Si les mises en phase apparaissent périodiquement avec la fréquence, alors c'est le signe d'un délai indépendant de la fréquence. Sinon c'est probablement du a la réponse de phase du low pass en sortie.
Oui j'affiche l'entrée et la sortie .
Je ne pense pas que ça soit le low pass en sortie : le déphasage serait le même à toutes les fréquences.
Je peux me tromper,mais pour l'instant je ne vois que la courbe de Nyquist qui peut faire ce "yoyo" de phase.
Mon soundcloud Good times !
besma mimi
j'ai un compte rendu et j'ai besoin de répondre à quelque questions:
1)l’effet de la fréquence d’échantillonnage sur la parole.
2)l’effet du codage sur l’analyse de la parole (PCM, MP3, MP2).
Merci a vous
Anonyme

A question oiseuse, réponse superfétatoire !
L'effet sur la parole est le même que sur le reste. La parole étant le son le plus connu de l'oreille humaine, elle y est le plus sensible. Mais, le signifiant l'emporte souvent sur les critères esthétiques et la dégradation par le système de diffusion et/ou le codec peut être plus acceptable tant qu'on n'a pas à faire d'effort pour comprendre le message. Tout dépend des circonstances, un commentaire sportif à la radio n'a pas les mêmes exigences qu'une cantatrice.
Le sujet est vaste et ta question bien vague.
JM
Lv mastering
..le codec peut être plus acceptable tant qu'on n'a pas à faire d'effort pour comprendre le message...
un commentaire sportif à la radio n'a pas les mêmes exigences qu'une cantatrice.
Oui, c'est trés important de pouvoir suivre le match dans de bonnes conditions tandis que l'opéra....on n'y comprend rien de toutes façons....
Studio de Mastering en ligne http://www.lvmastering.com/
Anonyme
Merci Lv pour ce post intéressant ![]()
JM
Lv mastering
La voix humaine peut être intelligible avec trés peu de bande passante. En téléphonie mobile, on a une bande 300hz à 3400hz et le débit aprés codage est de 16kbits/seconde.
Mais on est loin de la qualité d'un cd. On perd beaucoup de nuances et d'harmoniques par rapport au son original.
Studio de Mastering en ligne http://www.lvmastering.com/
philrud
Citation :
1)l’effet de la fréquence d’échantillonnage sur la parole.
Ben plus tu abaisses la fe (fréq.d'échantillonnage) ,plus tu réduis la bande passante dans le haut .Mais tout ça a déjà été dit et répété.
Donc pour la parole ,il faut connaître la bande de fréq. minimale à obtenir ,celle qui est la plus intelligible par l'oreille humaine et/ou celle que tu veux passer.Dans la parole il y a des "ssss" qui peuvent se transformer en "ffff" à l'écoute parce qu'on a réduit la bande passante à cause d'une fe plus basse ,alors on perd en intelligibilité .Comme les "c " peuvent se transformer en " fé" à cause d'une fe trop basse .Donc,il ya bien un impact sur l'intelligibilité de la fe pour une bande passante assez basse comme 2800hz ou bien 3400 hz .
En revanche pour une bande de 20khz (fe de 44.1kz) par rapport à une bande de 45khz (fe de 96khz) :on devrait entendre bien moins ou pas du tout la différence parcequ'elle est infime ou subtile surtout pour de la parole mais aussi pour l'oreille humaine.
En résumé : l'écart entre une bde de 2800hz et 3400hz =ça s'entend très bien.Mais l'écart entre une bde de 20khz et 45khz=ça s'entend peu , très peu ou pas du tout ; ça dépend ...Ce ne sont que 2 exemples ;mais on pourrait en faire plein plein d'autres en fonction de critères différents.
Pour la seconde question ,jan à répondu et je pense exactement pareil . ![]()
Mon soundcloud Good times !
EraTom
A noter que les codec destructifs (ils perdent une partie de l'information pour comprimer le plus possible le son) que tu donnes n'ont pas été conçus, à l'origine, pour l'encodage de la parole mais de la musique.
Quand tu réalises un état de l'art sur les techniques qui existent en encodage audio, tu trouves une famille d'algorithme spécifiques au traitement de la parole (d'un côté, et une autre famille de l'autre côté pour la musique) même s'ils existent, bien sûr, des points de convergences.
Les études des encodeurs pour la musique se sont d'abord focalisées sur l'étude et la caractérisation de spectres harmoniques (c'est ce que l'on rencontre le plus souvent à la base de ces algos).
Puis on y a ajouté des modèles "de bruits", pour prendre en compte tout ce qui n'était pas produit par une "somme de sinusoïdes" (comme le souffle d'un instrument à vent) afin d'en améliorer la qualité de restitution.
Aujourd'hui, on voit des tentatives pour encoder plus efficacement les transitoires et les sons percussifs en utilisant des sinusoïdes amorties exponentiellement et les atomes de Gabor (à la base des fameuses ondelettes).
Tu noteras par exemple que le mp3 s'en sort beaucoup mieux pour restituer un violon qu'un son de cymbale crash (la cymbale qui a le "mauvais goût" de cumuler un bruit percussif et un spectre étalé caractéristique d'un bruit).
Pour les traitements spécifiques à la parole, c'est un pari inverse qui a été fait à cause des spécificités du signal lui-même :
- Les variations sont rapides.
- On passe sans cesse de sons voisés (les voyelles), qui ont un spectre à peu près harmonique, à des consonnes occlusives (des plosives en franglish) comme le p,d,b,t,etc. et des consonnes fricatives comme le s, f, ch, etc. qui présentent des spectres de bruits.
Un codec comme le mp3 (ou mp2 qui est un mp3 "en moyen bien" pour faire court) s'appuie sur un modèles sinusoïdale (en cherchant à regrouper des harmoniques) est assez peu performant pour la parole.
Ce que tu vas plutôt trouver ce sont des familles d'algorithmes qui s'appuient sur des modèles autorégressifs.
https://fr.wikipedia.org/wiki/Processus_autor%C3%A9gressif
https://fr.wikipedia.org/wiki/ARMA
C'est ce qui est à la base du "Linear Predictive Coding" que tu as dans ton téléphone portable, par exemple :
https://en.wikipedia.org/wiki/Linear_predictive_coding
En gros, le principe est d'utiliser un générateur de bruit dont le spectre de fréquence va être modulé par un filtre en peigne. Les paramètres du modèle encoder sont la puissance du bruit (qui donne le "volume" ) et les coefficients du filtre / modèle AR (qui donne le contenu spectral). Note que je vulgarise à mort :p.
Ce genre de système donne de très bonnes performances pour la parole, meilleures que le mp3.
Tu me diras que la qualité du son de parole lors d'une conversation au téléphone portable est tout pourri par rapport à ce que tu obtiens avec l'encodage d'un CD en mp3. C'est vrai, mais il faut comparer des choses comparables :
- Le signal de parole d'un GSM est acquis en 8bits @8kHz alors que le CD est en 14bits @44kHz.
- Le débit du signal de parole encodé est de 13 kbps (13000 bits par secondes) alors qu'un mp3 de moyenne qualité est autour de 128 kbps... Il y a quand-même un rapport 10.
Je te garantis que si tu devais encoder un signal de parole en mp3 en partant d'un enregistrement à 8bits @8kHz pour arriver à 13 kbps tu obtiendrais une bouilli incompréhensible.
D'ailleurs, je ne sais même pas si les encodeurs mp3 proposent un débit aussi faible (je crois, mais c'est à vérifier, qu'ils ne descendent pas en dessous de 32 kbps et que c'est fixé par la norme).
A noter qu'une amélioration de l'encodage des GSM est à l'étude pour tomber à 7 kbps.
Cerise sur le gâteau, les modèles utilisés pour l'encodage de la parole permettent d'appliquer des traitements très efficaces pour rehausser le rapport signal à bruit et ils sont aussi assez robuste aux "bruits parasites" qui peuvent nuire à une bonne conversation.
Pour plus d'info, tu peux parcourir ce site :
https://perso.telecom-paristech.fr/~vallet/dom_com/bacuvier/cadrevocoding.html
(je ne crois pas que tu trouveras meilleur que Sup Télécom en France pour ce genre d'info).
besma mimi
- < Liste des sujets
- Charte