
Pour pouvoir être transmis sur des supports tels qu'Internet, le son est de plus en plus souvent numérisé et compressé. C'est de cet aspect que nous allons parler dans ce dossier.
De nos jours, de plus en plus de médias sont numérisés (image, son, vidéo…) et stockés ou transmis dans un format numérique. Cela a plusieurs avantages, dont le plus important est l’absence de perte de qualité du média numérisé pendant son transport ou lors de traitements sur celui-ci (à l’aide de logiciels, par exemple). Il existe également quelques inconvénients intrinsèques au caractère numérique, notamment la perte de précision lors du passage du monde analogique au monde numérique (appelé conversion analogique / numérique ou échantillonnage). Pour que le média numérisé soit rigoureusement le même que le signal d’origine, il faudrait numériser ce dernier avec une précision infinie, donc en stockant une quantité infinie d’informations… C’est évidemment très théorique et impossible à réaliser. En pratique, la limite de précision nécessaire est fixée généralement par celle du récepteur final de ce média : l’œil pour l’image, l’oreille pour le son. C’est ce dernier outil de l’homme qui nous intéressera le plus dans ce dossier, puisque nous traiterons principalement de la compression numérique du son.
Stockage de l’information et capacité limitée
Dans les studios professionnels, et même dans les home studios plus modestes, on se préoccupe généralement peu de la quantité d’information que l’on stocke sur son disque dur. Les stations sont de plus en plus performantes et la capacité des disques durs est mille fois plus élevée qu’il y a quelques années à peine. Du coup, on a tendance à stocker plus que nécessaire. Pour vous donner un ordre d’idée de la place que prennent vos enregistrements musicaux, voici quelques exemples :
- Un enregistrement en fichier « wav » d’un morceau de 4 minutes en qualité CD (44 Khz / 16 bits stéréo) : 42 Mo
- Ce même enregistrement de quatre minutes, mais en multipiste (chaque instrument est enregistré sur une piste séparée) avec le logiciel Samplitude de Sek’D par exemple, sur 8 pistes mono en 24 bits 96 KHz : plus de 550 Mo. Le morceau de musique prend bientôt toute la place contenue sur un CD audio, et ce pour un seul morceau de quelques minutes !
Faisons un tout petit peu de maths… La formule pour calculer la place prise par un enregistrement est simple. Soient :
- K la taille du fichier en Kilo-octets
- F la fréquence d’échantillonnage en KHz
- Q le nombre d’octets utilisés pour coder le signal (16 bits = 2 octets)
- P le nombre total de pistes mono (si vous avez des pistes stéréo, cela équivaut à deux pistes mono)
- T le temps de l’enregistrement en secondes
K = P * F * Q * T
A l’inverse, on trouve sur Internet des fichiers audio de quelques mégaoctets, d’une qualité plus qu’honorable. Ceci est rendu possible grâce à la compression numérique. Nous allons expliquer les différentes manières de procéder pour la compression et voir quel type de compression choisir en fonction du contexte.
Compression non destructive
Algorithmes de compression généralistes
Vous connaissez certainement de multiples formats de compression dits « non destructifs ». La compression zip, bien connue en informatique, en fait partie. La propriété principale des algorithmes non destructifs est qu’une fois décompressé, le fichier est rigoureusement le même que le fichier avant compression (au [def]bit[/def] près). Il n’y a donc aucune perte d’information. Comment peut-on réduire la place prise par un fichier tout en gardant toute l’information contenue dans celui-ci ? Pour simplifier, disons que l’algorithme de compression (prenons ici l’exemple du .zip) recherche dans le fichier des occurrences multiples d’une suite d’octets. Il se crée ainsi ce que l’on appelle un dictionnaire, index qui référence ces suite d’octets répétitives. Ensuite, l’algorithme remplacera celles-ci, dans le fichier compressé, par des codes qui prennent moins de place.
Prenons un fichier texte, par exemple cet article que vous êtes en train de lire. Dans celui-ci, vous retrouvez souvent les mots « compression », « destructive », « son », « fichier ». L’algorithme de compression va alors se créer une table de correspondance pour dire « compression » = 1, « destructive » = 2, « son » = 3, « fichier » = 4. Ainsi, dans le texte, ces mots vont être remplacés par leur code, plus court, donc prenant moins de place dans le fichier compressé. Voilà donc, de manière simplifiée, le fonctionnement de la compression non destructive. Sans trop rentrer dans les détails, sachez que la compression (zip ou autre) se fait de manière intelligente et plus complexe que selon le principe énoncé précédemment. Par exemple, on a recours à l’algorithme de Huffman, qui optimise le codage des données, puisqu’il encode les mots les plus fréquemment trouvés avec le code le plus court possible, et garde les codes les plus longs pour les mots les moins fréquents. Par exemple, le chiffre 1 peut être codé sur un seul bit (alors que le mot « compression » est codé sur au moins 11 octets, soit 88 bits !). Imaginons que le dictionnaire comporte 1000 mots. A titre d’exemple, on pourra se permettre de coder un mot comme « fonctionnement », trouvé plus rarement dans le texte, sur 10 bits (10 étant ici le nombre de bits maximum pour coder 1000 mots, puisque 2^10 = 1024).
D’autres formats de compression non destructive sont plus performants que le ZIP : le RAR ou le ACE entre autres. Voilà en ce qui concerne les algorithmes non dédiés à l’audio.
Limites des algorithmes généralistes
Parlons maintenant de ce qui nous intéresse le plus : le son. Nous avions pris l’exemple d’un texte, et c’était particulièrement commode parce que ce type de média contient beaucoup de répétitions, donc peut se compresser très facilement. Il en va tout autrement dans le cas de l’audio, car le caractère très changeant du son fait qu’il est rare de retrouver des répétitions fidèles dans celui-ci. En effet, la décomposition du son selon Fourier nous limite au cas d’un signal purement périodique, mais en réalité une onde sonore ne se répète jamais rigoureusement de la même façon. A cette règle font exception les sons générés par des oscillateurs de base (ondes sinusoïdales, triangulaires, etc.), au travers d’un logiciel ou d’un synthétiseur virtuel. Même dans le cas d’un synthétiseur réel, le son varie légèrement et de manière non prévisible, comme nous allons le voir dans l’exemple suivant.
J’ai fait le test avec deux enregistrements de cinq secondes d’une onde en dent de scie. L’une est créée avec Sound Forge (donc parfaitement périodique) appelée et l’autre provient d’un bon vieux synthétiseur analogique, le Roland Juno 106. L’enregistrement de ce dernier fait intervenir la stabilité relative du son des synthétiseurs analogiques, et fait apparaître nécessairement du bruit de fond. Les deux sons étant de même durée à l’échantillon près, les fichiers non compressés correspondants font la même taille, 862 Ko. Après compression avec l’algorithme utilisé par le format ZIP, le premier se compresse énormément et passe à 7 Ko, et l’autre beaucoup moins, étant réduit à 38 Ko. Ceci dit la différence dans le cas général est encore plus flagrant. Dans le cas de l’enregistrement de l’onde sinusoïdale du Juno 106, nous avons affaire à un son très stable (quasi périodique). Par conséquent, ce qui est à retenir est la différence d’efficacité en fonction du son à encoder. En revanche, le facteur de compression n’est ici pas représentatif de l’efficacité de tels algorithmes sur un son, à cause de la périodicité du signal d’origine. En effet, un son plus complexe se compresse beaucoup moins bien, comme nous le verrons tout à l’heure.
Algorithmes dédiés au son
Passons à présent à un exemple de son complexe. Sachez que de nombreux algorithmes propres à ce type de média existent, bien qu’ils soient moins connus. Citons WavArc (.ARC), tiré du format de compression ARC de Dennis Lee, AudioZIP (.zip), tiré du ZIP de Lin Xiao, LPAC de Tilman Liebchen, Monkeys Audio de Matthew T. Ashland, et enfin RKAU de Malcolm Taylor.
Lors de mes tests comparatifs, le RKAU (Pour RK Audio) m’a particulièrement plu pour plusieurs raisons. D’une part, il est le plus efficace de tous les algorithmes non destructifs cités. D’autre part, la compression avec cet encodeur s’effectue rapidement. Enfin, le logiciel est gratuit et il est fourni avec un plug-in pour Winamp, ce qui signifie que vous pouvez directement écouter les sons compressés au format RK Audio dans ce player. Vous trouverez ce programme ici (rkau107.zip).
Sound Forge propose quant à lui un format propriétaire, le Perfect Clarity Audio (dont l’extension des fichiers est le PCA). Dans l’exemple précédent, le son est périodique, si bien que la comparaison de cet algorithme avec le ZIP ou le RAR est biaisée, puisque ce format, censé être particulièrement adapté au son, donne de moins bons résultats que le ZIP. La raison est simple : le son est trop périodique, sa compression peut donc être assimilée à celle d’un fichier texte dans lequel on aurait recopié des centaines de fois le même paragraphe. Loin de moi l’idée, donc, de dénigrer le format développé par Sonic Foundry ! Pour preuve, si l’on prend l’extrait sonore son_complexe.wav, la compression par l’algorithme Perfect Clarity Audio donne de bien meilleurs résultats que le ZIP ou le RAR.

Comparaison des tailles de fichier entre compression destructive et non desctructive
Cependant, malgré la compression, les fichiers audio sont encore trop volumineux pour être utilisés dans certains contextes : dans l’utilisation de tels fichiers sur Internet, certes, mais aussi dans les canaux de transmission numériques comme le câble télévisé. On a donc recours à un autre type de compression : la compression destructive.
Compression destructive
Comme je le disais tout à l’heure, la limite de précision que les entreprises se fixent lorsqu’elles créent un produit diffusant de l’audio est calquée généralement sur les limites des sens de l’homme. Reprenons l’exemple du paragraphe précédent. L’onde en dent de scie provenant du synthétiseur analogique est accompagnée d’un bruit de fond, et c’est principalement ce bruit de fond qui rend le fichier non répétitif, donc compressible difficilement. En effet, par définition un bruit est une onde totalement chaotique. On ne peut donc pas trouver deux occurrences identiques dans un tel signal. Pourquoi garder cette information, non nécessaire, dans le fichier sonore ? C’est sur ce genre de constatations que la compression destructive se base.
Il existe également de multiples formats de compression destructive. Il faut savoir que l’un d’entre eux, le très connu MP3, a été créé et breveté par Thomson Multimedia. Aussi, théoriquement, chaque personne qui crée un fichier MP3 pour l’exploiter commercialement est censée reverser des droits à l’entreprise. Le format imposé par Microsoft, le Windows Media Audio (WMA), ressemble au MP3. Il est réputé être légèrement de meilleure qualité pour une même taille de fichier. Son format est également breveté donc son utilisation se fait en contrepartie de droits reversés à Microsoft. Bien sûr, ces problèmes de droits ne sont à considérer que si vous êtes de grandes entreprises comme Mp3.com (Universal) ou que vous vendez des players MP3 / WMA en grande quantité. A petite échelle, personne ne viendra vous demander des royalties ! Le format OGG Vorbis quant à lui résout ces problèmes de brevet. C’est un format quasi identique au MP3, à la différence que l’utilisation de celui-ci est libre de droits. Malheureusement, ce format n’est pas aussi répandu que le MP3 ou le WMA.
Parmi les autres formats de compression destructive, citons le MP3Pro, évolution du bien connu MP3, le Real Audio de Real Networks, le Yamaha VQF. Les algorithmes utilisés sont principalement le MPEG (pour le format MP3), l’AAC (MP3Pro), l’ATRAC (Sony Minidisc), le PASC (Philips DCC), et enfin les Dolby AC-1, AC-2 et AC-3. Un petit mot sur le MP3Pro au passage : puisque ce format s’avère de meilleure qualité que le MP3 pour une réduction encore plus grande de la quantité d’informations stockées, pourquoi ne pas utiliser exclusivement le MP3Pro ? La raison est que le temps de calcul nécessaire à décompresser un tel format est élevé. Ainsi, décompresser un morceau en MP3Pro risque de consommer toutes les ressources de votre ordinateur et de n’en laisser à aucune autre application.
Afin de définir les différentes techniques utilisées pour compresser le son, nous allons principalement nous appuyer sur le format MP3 (Mpeg 2 layer 3), format audio utilisant typiquement la compression destructive, donc les limites psychoacoustiques de l’oreille humaine, afin de supprimer certaines parties du son inaudibles.
Le masquage de fréquences
L’une des propriétés les plus intéressantes parmi celles utilisées pour ne pas « encoder l’inutile » est la technique de masquage. Le seuil à partir duquel l’oreille humaine perçoit un son dépend énormément de la fréquence de ce son. Par exemple, nous percevons beaucoup plus facilement un son faible à 4 kHz qu’à 50 Hz ou 15 kHz. De plus, à partir de 25 kHz, quel que soit le niveau sonore, l’oreille humaine ne perçoit plus aucun son. Le MP3, tout comme les Mini-Disc et le Dolby, utilise donc la technique de masquage : si deux sons de fréquences proches sont joués avec une intensité très différente, on pourra supprimer le son le plus faible qui sera de toute façon masqué et ignoré par l’oreille humaine.
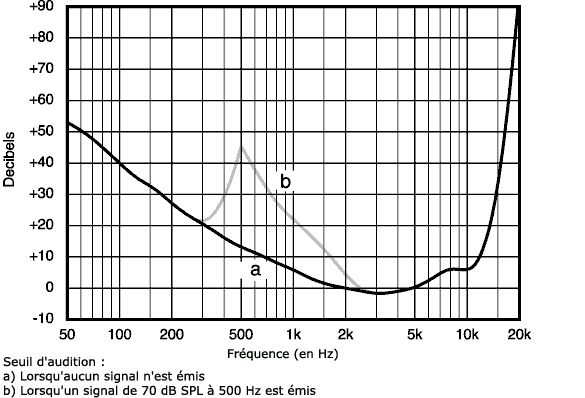
Le phénomène de masquage de fréquences
Le graphe ci-dessus met en relief le phénomène de masquage de fréquences. En effet, en présence d’un signal de 500 Hz, un son d’une fréquence proche de 500 Hz est masqué et son niveau doit dépasser la courbe b pour être audible par l’oreille humaine. Si son niveau est en dessous, on n’est pas obligé d’en tenir compte dans le fichier compressé.
Le Joint Stereo
Prononcez à l’anglaise ! Il ne s’agit pas d’une invention Hippie de dernière génération, mais d’un processus appelé « stéréo jointe » en bon français. Ce qui était valable pour la compression non destructive l’étant aussi pour la compression destructive, la taille du fichier est directement proportionnelle au nombre de pistes enregistrées. Enregistrer en mono prend donc deux fois moins de place que d’enregistrer en stéréo ! Or un autre aspect de l’oreille humaine est sa capacité limitée à localiser la provenance des basses fréquences dans l’espace de diffusion, contrairement aux hautes fréquences dont on distingue facilement la provenance. Ainsi, pourquoi coder les basses en stéréo ?
C’est ce principe qui est utilisé avec le « Joint Stereo » : le spectre du signal est coupé en hautes et basses fréquences, les hautes fréquences étant codées en stéréo, et les basses en mono… Et il est difficile d’entendre la différence, la plupart du temps. Notez que l’on a généralement le choix d’activer ou non le Joint Stéréo lors de l’encodage. Si votre morceau fait intervenir des basses qui ont une image stéréophonique large (ce qui est rare, l’énergie des basses étant à centrer dans un bon mix), vous pouvez préserver cet aspect du morceau.
L’algorithme de Huffman
Une fois de plus, Huffman a frappé. Son algorithme consiste, un peu comme précédemment, à rechercher, une fois le son encodé, des occurrences identiques (minuscules samples comme une période de sinusoïde par exemple). C’est rarement le cas dans un morceau complexe, mais cela peut l’être dans une partie éthérée d’un morceau. A ce moment là, chaque occurrence est codée et au lieu d’enregistrer n fois la même occurrence, on indiquera simplement un code de quelques bits y faisant référence.
Paramètres de la compression
Lorsque nous voulons encoder un fichier sonore, nous disposons de plusieurs options. Celui qui détermine le plus la qualité du son compressé final est le « Bitrate », qui est en fait le débit consommé lors de la transmission du fichier. Par exemple, en 128 kbps, le fichier devra, pour être écouté en temps réel (« streaming » en anglais) être téléchargé à la vitesse de 128 kilo bits par seconde (16 Ko par seconde). Ceci est impossible à faire avec un modem en 56 Kbps contrairement à l’ADSL qui permet généralement au moins 4 fois cette bande passante.
Vous disposez en outre de l’activation ou non du système de stéréo jointe. Parfois il peut être préférable de désactiver cette option. Néanmoins cela a pour conséquence de devoir enregistrer plus d’informations pour coder le signal. Comme la limite de quantité d’informations est strictement fixée par le bitrate, le son stéréo devra être codé avec moins de précision pour contrer l’augmentation d’informations à coder résultant du fait qu’il faut coder deux canaux, et sera donc de moins bonne qualité.
Enfin, les créateurs du MP3 ont fait la constatation suivante : dans un morceau, on trouve des passages sombres ou silencieux. Pourquoi les coder de la même manière que les passages très brillants et complexes ? Ils ont donc amélioré le format MP3 grâce à l’implémentation du « Variable Bit Rate » (VBR). Ce système permet de faire varier dynamiquement le bitrate du codage en fonction de la complexité du son. Ainsi un passage sombre sera codé en 16 Kbps au lieu de 128.
L’ensemble des paramètres de compression dans le logiciel CDEx
Conclusion
Alors, que choisir ? Une compression destructive, non destructive, aucune compression ? Les professionnels du son vous le diront tous (parfois avec un mépris des plus troublants) : la compression destructive est une calamité. En effet, pourquoi se fatiguer à travailler le mix d’un morceau en finesse, l’échantillonner en 24 bits / 96 KHz, faire attention à la qualité du son dans les moindres détails, si c’est pour finalement utiliser une compression destructive et ainsi perdre tous les détails du morceau ? Et pourtant, la télévision et la radio numériques, de même que la transmission de médias sur Internet, utilisent la compression destructive (principalement le MPEG) pour permettre d’envoyer le flux d’informations en temps réel. Il serait inimaginable de transmettre du son non compressé via les canaux de transmission dont nous disposons actuellement.
La conclusion de cette réflexion est la suivante : si vous travaillez en local, chez vous, et que vous avez de la place de votre disque dur, passez-vous de compression. Au pire, si vous utilisez majoritairement des produits de Sonic Foundry (Acid, Sound Forge…) vous pouvez compresser en PCA sans aucune perte de qualité sonore. Vous pourriez également archiver les anciens morceaux en les compressant en RK Audio. En revanche, dès que vous voulez diffuser vos morceaux sur un media à bande passante limitée (comme Internet), vous devez utiliser la compression destructive comme le MP3.
Bibliographie
Voici une liste de sites utilisés lors de la rédaction de cet article :
Site de Thomson Multimedia, à l’origine du MP3
http://mp3licensing.com
Site de l’institut de Fraunhofer dédié à l’audio et au multimedia
http://www.iis.fhg.de/amm
Comparatif d’algorithmes de compression non destructive
http://www.firstpr.com.au/audiocomp/lossless
Tout sur la compression MPEG
http://www.mpeg.org
Détails sur l’algorithme ATRAC utilisé dans le minidisc
https://www.minidisc.org
Site officiel de l’encodeur gratuit CDEx
http://www.cdex.n3.net
Je vous invite à visiter ces sites pour en savoir plus.
