
La musique électronique n'a pas su imiter de façon satisfaisante les sons instrumentaux, même en s'aidant de synthèses de Fourier fondées sur des analyses préalables. Notamment, les sons qui évoluent dans le temps ne pouvaient être reconstitués par des générateurs sonores au timbre fixe. Le traitement numérique a heureusement permis de prendre en compte les variations dans le cours même du son.
Comment aborder le thème de la synthèse sonore le plus exhaustivement possible, le domaine étant vaste ? Nous allons voyager à travers la création sonore, de la source de base à l’interprétation, pour découvrir chaque étape de son élaboration.
Le XIXème a vu l’essor de l’analyse sonore. Fourier explique mathématiquement la notion de composante harmonique, et donne son fondement et sa justification à la démarche d’analyse et de synthèse sonore. Le traitement électrique fut néanmoins nécessaire à l’élaboration de synthèses sonores plus poussées que les simples mutations de l’orgue réussies initialement.
Vers 1951, Eimert, Meyer-Eppler et Stockhausen deviennent à Cologne les pionniers de la musique électronique, qui partait de vibrations sonores électriques : il s’agissait de produire des sons aux paramètres biens contrôlés, suivant les prescriptions de partitions existant a priori et construites suivant des règles formelles très précises. En 1957, Max Mathews réalise aux USA le premier enregistrement numérique et la première synthèse de sons par ordinateur.
Aujourd’hui, la synthèse prend son essor avec les nouveaux synthétiseurs et les nouveaux logiciels dédiés au son. Ce progrès est de plus poussé par l’augmentation de la puissance des processeurs, qui permettent un traitement sonore poussé (par des DSP, processeurs dédiés à la vidéo et à l’audio).
Le traitement sonore est de plus réalisé à tous les niveaux, notamment lors de l’enregistrement et de la reproduction de la musique sur support magnétique : afin d’éliminer le souffle dans un enregistrement, on a recours au traitement de réduction de bruit (Noise reduction) Dolby NR.
Enfin, le traitement sonore a des applications dans de nombreux domaines, et analyser le spectre sonore par exemple lié à la voix a permis ensuite l’apparition de la reconnaissance vocale.
Définition du son
1. Qu’est ce que le son ?
Le son est la sensation auditive engendrée par une onde acoustique due à la vibration d’un corps. Le son est transmis à travers toute matière qu’il peut déformer pour se propager (on en déduit qu’il se propage bien dans l’air, moyennement dans les liquides et difficilement dans les solides).
Le son est caractérisé :
- Par sa hauteur, qualité qui fait distinguer un son grave d’un son aigu. La hauteur d’un son est liée à la fréquence de vibration de la source sonore. Les sons aigus sont dus au mouvement vibratoire de fréquence élevée et les sons graves au mouvement de basse fréquence. Toutefois, l’oreille ne peut percevoir que les sons dont les fréquences sont comprises entre 20 et 20000 Hz environ, soit une dizaine d’octaves.
- Par son intensité, qualité qui fait distinguer un son fort d’un son faible. L’intensité est liée à l’amplitude des vibrations sonores. Toutefois, l’oreille ne peut percevoir un son que si cette amplitude a une valeur minimale. L’intensité minimale correspondante s’appelle « seuil d’audibilité ». Si, au contraire, on fait croître progressivement l’amplitude des vibrations sonores, l’audition finit par devenir extrêmement pénible. L’intensité maximale correspondant à la limite du supportable pour l’oreille est appelé « seuil de douleur ».
- Par son timbre, qualité qui permet de distinguer deux sons émis par deux instruments différents. Si le son est « musical » au sens acoustique du terme, c’est à dire créé par un mouvement vibratoire périodique, on montre que le son peut être considéré comme la superposition de sons simples harmoniques, dont les fréquences sont des multiples entiers de la fréquence d’un son de base, appelé fondamental. Le timbre d’un tel son dépend des intensités relatives des différents sons simples harmoniques qui le composent.
2. Perception des niveaux sonores
- Limites perceptives
La perception d’un son pur existe dans l’intervalle 20 Hz-20 kHz. Cet intervalle se réduit inexorablement avec l’âge. La « presbyacoustie » correspond à la perte de cette acuité auditive. La destruction de cellules est irrémédiable et irréversible.
- Dynamique
L’oreille n’est sensible qu’à 50 dB de dynamique dans les graves, à comparer avec les 120 dB de dynamique aux alentours de 3 kHz (à comparer également avec la dynamique plus faible des instruments de mesure).
La chaîne des osselets (marteau, étrier et enclume) permet d’adapter l’impédance acoustique du milieu extérieur à celle de l’oreille interne. Il existe des mécanismes réflexes permettant de modifier dynamiquement le facteur d’adaptation acoustique de la chaîne des osselets afin d’augmenter ou de diminuer le ratio d’énergie transmis à l’oreille interne. Ce mécanisme s’apparente à celui de la pupille de l’œil agissant comme un diaphragme, laissant entrer plus ou moins de lumière à l’intérieur de la cornée. Ce phénomène permet de supporter des sons forts pendant des durées assez longues.
3. Perception des hauteurs
-
Périodicité
La périodicité (phénomène temporel) est le principal phénomène physique à mettre en rapport avec la perception de hauteur. Par exemple, tous les sons possédant une période de 10 ms, seront jugés comme des sons possédant la même hauteur (hauteur tonale), et en particulier la même hauteur qu’une sinusoïde à 100 Hz.
- Harmonicité
D’un point de vue fréquentiel, la périodicité d’un son entraîne une répartition harmonique de ses partiels (qui sont les différentes fréquences de résonance d’un instrument). Donc, si nous devions énoncer une règle pour mesurer la hauteur perçue d’un son périodique à partir de son spectre, nous dirions qu’il s’agit de déterminer le plus grand commun diviseur (PGCD) des fréquences de tous les partiels harmoniques. Cette fréquence s’appelle fréquence fondamentale (ou encore la fondamentale) d’un son.
- Pièges
Si la fréquence fondamentale d’un son n’est pas la fréquence du premier partiel harmonique, dit le fondamental, nous sommes alors dans le cas du fondamental absent. Il s’agit par exemple de sons creux, tels que celui du basson. A part un timbre un peu pauvre, cette situation n’a rien d’extraordinaire ou étonnante ; au niveau de la forme d’onde, rien de particulier ne distingue ce cas du cas où le fondamental est présent. Nous sommes dans le cas où il manque de nombreux partiels dans le son. Dans le cas de la clarinette, il manque approximativement un partiel harmonique sur deux, caractéristique de cette sonorité un peu nasillarde.
- Ambiguïté d’octave
La hauteur des sons est ambiguë à une octave près. Un son à 200 Hz et un son à 400 Hz produisent tous les deux une sensation de hauteur assez semblable. Cela tient au fait que si mathématiquement 2.5ms est une période du signal (400 Hz) alors, 5ms est nécessairement une autre période du signal (200 Hz).
L’importance du rapport d’octave est très largement utilisée en musique, en particulier pour définir des classes de hauteurs (Do, Ré, Mi… sont définis à une octave près, et définissent ainsi une classe de hauteur).
- Perception différentielle
La perception de la hauteur, est, comme la plupart des phénomènes perceptifs, régie essentiellement par une échelle logarithmique.
La perception de la hauteur du son change en fonction de son intensité sonore et en fonction du niveau du bruit ambiant. Cette déviation de perception de hauteur dépend également de la hauteur du son.
- Oreille absolue
Normalement, nous ne sommes capables de percevoir que des rapports de hauteurs. En d’autres termes, nous nous souvenons sans difficulté de la mélodie de « Au clair de la Lune », mais nous reconnaissons toutes les mélodies transposées (c’est à dire décalées d’un nombre fixé de demi tons) également comme « Au clair de la Lune ». Donc les mélodies de hauteurs reposent principalement sur l’enchaînement des rapports de hauteur, et non pas sur les hauteurs proprement dites.
Certains individus sont toutefois capables de percevoir la hauteur des sons, de la mémoriser, et de la comparer avec d’autres hauteurs. Cette caractéristique s’appelle l’oreille absolue. C’est une caractéristique génétique, et fait donc partie de l’inné. Si on la possède, elle se cultive, sinon elle ne s’apprend pas.
Les différentes synthèses sonores
1. La synthèse analogique
La synthèse analogique consiste à créer, à partir d’oscillateurs de base(générateurs de signaux électriques), un son.
Exemple : onde carrée
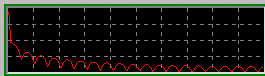
Décomposition de Fourier d’une onde carrée.
Les ondes de base générées sont souvent les ondes triangulaires, en dent de scie, carrées, sinusoïdales, impulsionnelles, etc.
Plusieurs oscillations sont généralement superposées pour donner un son dense et riche en harmoniques, souvent trop riche. Le traitement de l’onde qui s’en suivra sera de type soustractif, c’est à dire que des modules (filtres) vont enlever certaines harmoniques au son.
2. La synthèse FM
La synthèse FM (à modulation de fréquence) fonctionne sur un autre principe. Elle consiste à moduler l’onde de base de manière non linéaire. Elle permet donc, à partir d’une sinusoïde, de créer une onde complexe, comme on peut le voir clairement ci dessous :
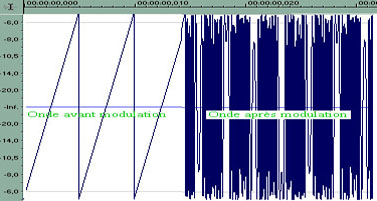
Onde en dent de scie de 100 Hz modulée par une onde sinusoïdale de 400 Hz (Document : Sound Forge)
3. La synthèse numérique
Plus récente que les synthèses analogique et FM, la synthèse numérique utilise un tout autre procédé : un synthétiseur ou un sampler qui joue des échantillons sonores enregistrés et mémorisés dans une banque de sons. Il est capable, en lisant un échantillon plus ou moins vite, de transposer le son et ainsi de couvrir plusieurs octaves.
Le désavantage de ce type de procédé est qu’un son est plus court lorsqu’il est joué plus aigu, plus long lorsqu’il est joué plus grave, ce qui est incompatible avec un son acoustique dont la durée est indépendante de la hauteur de la note.
L’avantage certain est que les sources sonores de base sont infinies, et non plus limitées par quelques oscillateurs comme dans le cas de la synthèse analogique.
Qu’est-ce que la numérisation ?
L’opération de numérisation se réalise en théorie en deux étapes :
- échantillonnage,
- quantification.
L’échantillonnage consiste à passer d’un signal à temps continu (un signal électrique, un signal acoustique…), en une suite discrète de valeurs (valeurs mesurées à intervalles réguliers).
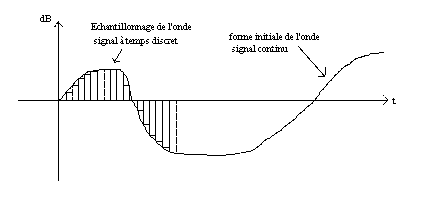 |
Signal discret – signal continu
- Signal à temps continu : par exemple :
la hauteur du bouchon qui flotte sur l’eau,
le signal électrique qu’utilise un amplificateur audio,
le signal hertzien de modulation d’amplitude (AM), ou de fréquence (FM),
la vitesse d’une voiture…
- Signal à temps discret :
les mesures quotidiennes du taux de globules rouges dans le sang
la donnée de la température au bulletin météo tous les matins
le pourcentage de spectateurs regardant le journal de 20h d’un chaîne de télévision
les mesures régulières de l’activité d’un volcan…
-
Interprétation temporelle
L’interprétation temporelle est très simple : on mesure périodiquement la valeur d’un signal à temps continu. Par exemple, on mesure la vitesse d’une voiture toutes les 10 secondes et on reporte les points sur un graphe. Chaque mesure s’appelle un échantillon. La période d’échantillonnage est la période de temps séparant deux échantillons successifs. La fréquence d’échantillonnage ou taux d’échantillonnage s’exprime en hertz, et correspond à l’inverse de la période d’échantillonnage (un période d’échantillonnage de 10 s correspond à une fréquence d’échantillonnage de 0,1 Hz).
Dans un premier temps, la reconstruction du signal n’est possible que si les variations de celui-ci sont assez lentes, ou réciproquement si la période d’échantillonnage est assez fine.
La reconstruction en pratique consiste à maintenir constante la valeur de l’échantillon jusqu’à l’arrivée de l’échantillon suivant.
- Interprétation fréquentielle
D’un point de vue théorique, l’échantillonnage correspond à la « périodisation » du spectre. En conséquence, l’intégrité du signal est maintenue tant que les copies (les alias en anglais) du spectre ne se superposent pas l’une sur l’autre. Le phénomène de recouvrement des spectres est nuisible et s’appelle le repli spectral (ou aliasing en anglais). Une conséquence de cette interprétation est l’obtention du théorème d’échantillonnage : pour éviter le repli spectral, il faut et il suffit que le signal original soit à bande limitée et que la fréquence d’échantillonnage soit supérieure à deux fois la bande utile du signal. En pratique, le signal audio utile est limité par notre perception, c’est-à-dire 16 kHz, donc, la fréquence d’échantillonnage doit être supérieure à 32 kHz. Pour que le signal audio respecte les conditions du théorème d’échantillonnage, il faut s’assurer d’avoir éliminé toutes les composantes hautes fréquences à l’aide d’un filtre anti-repliement (anti-aliasing).
- Effet du repli spectral
Le repli spectral est nuisible :
en vidéo où la chemise à rayures fait un moirage à l’écran,
au cinéma ou à la télévision où les roues des voitures et des charrettes semblent tourner au ralenti dans un sens ou dans l’autre.
-
Pratique de l’échantillonnage
Les signaux sonores ont en général peu d’énergie à haute fréquence.
La qualité de l’échantillonnage et de la restitution sonore dépend essentiellement de la qualité du filtre analogique anti-repliement. En particulier, le prix des cartes audio pour les ordinateurs personnels est essentiellement déterminé par la qualité des convertisseurs (et donc de la qualité des filtres anti-repliement). Par exemple, de nombreuses cartes bon marché ne possèdent pas de filtres anti-repliement adaptées à toutes les fréquences d’échantillonnage proposées.
La reconstruction avec des dispositifs bloqueurs induit une génération de composantes hautes fréquences non désirées. Il est nécessaire d’utiliser un filtre du même type que le filtre anti-repliement pour la conversion numérique/analogique.
Les techniques évoluées d’échantillonnages consistent à sur-échantillonner / sous-échantillonner. D’un point de vue théorique, cela consiste à déplacer le problème du filtrage anti-repliement du domaine analogique dans le domaine numérique, ce qui coûte beaucoup moins cher. C’est ce que l’on voit affiché sur les spécifications techniques des lecteurs de CD audio.
4. La synthèse à modélisation physique
Comme nous le verrons, un son acoustique est identifié par l’oreille humaine par certains caractères propres à l’instrument (attaque, évolution harmonique). Ainsi, il est venu récemment à l’idée des ingénieurs du son d’analyser les caractères audibles de l’instrument et de recréer par un algorithme certains de ces caractères : la forme de l’instrument, le matériau, le constituant, etc. Ainsi, il est à présent possible, par exemple, de créer virtuellement un violon en cuivre !
Créer un timbre
1. La dynamique dans un son
a) Évolution en volume : l’enveloppe d’un son
Un instrument crée un son dont l’amplitude sonore n’est pas constante, sinon il paraîtrait terne. Ainsi, on définit l’enveloppe du son, qui traduit son évolution au cours du temps.
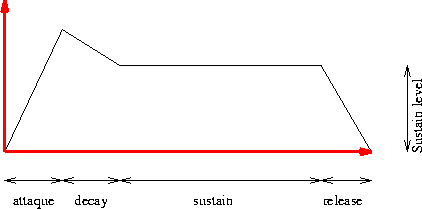 |
b) Évolution harmonique du timbre
Il existe une enveloppe de volume sonore comme il existe une enveloppe des harmoniques existant dans un son.
En modulation de fréquence (synthèse FM), l’enveloppe temporelle de l’oscillateur associé à la porteuse contrôle les caractéristiques temporelles du son synthétique. Par contre, l’enveloppe temporelle du second oscillateur contrôle l’évolution temporelle du timbre du son synthétique. L’évolution de l’indice de modulation selon le schéma attaque, decay, sustain, release vu précédemment contribue à générer un spectre très riche pendant l’attaque, stable pendant la phase tenue et une phase de résonance classique où tous les partiels (ou harmoniques) décroissent progressivement à des rythmes différents.
2. Les traitements : les filtres
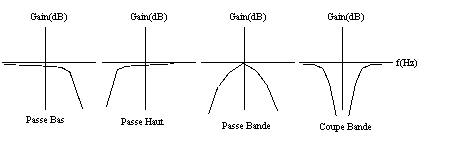
Les filtres consistent à supprimer certaines fréquences dans un son. Il existe différents filtres :
- Le filtre passe bas : il laisse passer les basses fréquences et coupe les hautes fréquences à partir d’une fréquence donnée appelée fréquence de coupure.
- Le filtre passe haut : inversement, il laisse passer les hautes fréquences et coupe les basses fréquences.
- Le filtre passe bande : il ne laisse passer qu’une bande de fréquences.
- Le coupe bande : il retire une bande de fréquences.
 |
- Le passe tout : mais à quoi peut-il bien servir, s’il laisse passer toutes les fréquences ? Il crée un déphasage différent selon la fréquence de coupure.
3. L’interprétation : une partie intégrante du son
Le son étant créé, il faut bien prendre en compte que lorsqu’il est exploité, il doit varier pour prendre de la valeur : ainsi, un son n’est pas rigide mais son enveloppe, son volume, les harmoniques présentes varient en fonction du jeu (via les filtres par exemple).
Les effets sonores
1. Équalisation
L’équalisation consiste à augmenter ou diminuer une gamme de fréquences autour d’une fréquence fixée.
a) Filtres
A cet étape les filtres sont encore présents, notamment :
-
Les filtres passe bas pour retirer certains parasites, utilisés surtout lorsque le son d’origine ne contient que peu d’aigus, car sinon, on assourdirait le son en le filtrant.
-
Les filtres Passe haut, à 75 Hz sur la plupart des tables de mixages, car les ondes entre 20Hz et 75 Hz ont sont imposantes et assourdissantes, et conviennent pour une grosse caisse, mais une basse acoustique doit être parfois modérée par un tel filtre.
b) Équalisation et facteur Q
L’équalisation joue un rôle important dans la finalisation d’un son, donnant son caractère : elle permet de contrôler le timbre ou la coloration d’un signal audio en modifiant la réponse en fréquences d’un son source.
Un équaliser possède donc une fréquence d’équalisation, c’est à dire la fréquence autour de laquelle le volume va être accentué ou diminué. Cette fréquence est fixe ou variable (équalisers semi-paramétriques).
| Cliquez ici pour afficher l’image associée : réponse en dB en fonction de la fréquence des EQs passe haut (1) et passe bas (2) fixes. |
Enfin intervient dans les caractéristiques d’un équaliser son facteur Q : c’est la largeur de la bande de fréquences affectées, rendant l’équaliser plus ou moins résonant. Lorsque le facteur Q est réglable, l’équaliser est dit paramétrique.
| Cliquez ici pour afficher l’image associée : réponse en dB en fonction de la fréquence d’un équaliser paramétrique 1 bande. |
Généralement sur une table de mixage, les équalisers fixes ont un faible facteur Q pour assurer une bonne transition vers les fréquences adjacentes.
c) Résonateur
Un résonateur est un filtre spécial dont la réponse (la largeur de bande) est si étroite (Facteur Q très grand) qu’il donne une harmonique très présente quel que soit le signal passant au travers. On peut ainsi accentuer diverses harmoniques du son d’une guitare, ce qui peut changer totalement le caractère du son.
2. Effet de Pitch
Les effets de pitch modifient la hauteur d’un signal de différentes façons de manière à produire des timbres superposés qui sont plus complexes que le signal originel. Ils s’obtiennent en séparant le signal en deux, affectant la modification du pitch à une partie, puis en les mixant.
Les effets décrits ci dessous sont monophoniques, mais on peut malgré tout obtenir des effets stéréophonique, par combinaison de deux effets monophoniques.
a) Chorus
L’effet de Chorus est obtenu en prenant une partie du signal d’origine, en la retardant légèrement(de 0 à 100 ms), et en changeant légèrement sa tonalité, appelé detune. Le detune est modulé par un LFO faisant varier sa hauteur.
Il existe d’autres types de Chorus, comme le chorus quadratique, qui module quatre signaux retardés, chacun avec un décalage de phase de 90°.
b) Flanger
Le flanger est similaire au chorus, mais il module le signal retardé selon une plage de temps plus courte (0 à 12 ms). Cela produit un son type « avion ».
D’abord utilisé dans les années 60, le « flanging » était obtenu à l’aide de deux magnétophones à bande qui enregistraient et jouaient la même chose en synchronisation. En ralentissant une machine puis en la laissant se recaler sur l’autre, différentes annulations de phase intervenaient à différentes fréquences.
L’effet de flanging est obtenu en séparant et retardant légèrement une partie du signal, puis en faisant varier le temps de retard avec un LFO. Le signal retardé est alors mixé avec le son d’origine pour produire un « bruissement ».
c) Phaseur
Un autre effet très connu est le phaseur. Bien qu’étant similaire au Flanger, l’effet est produit différemment. Une partie du signal est séparée de nouveau du signal d’origine. Le phaseur décale la phase de différentes fréquences et de différentes valeurs, donnant un effet de filtres combiné avec le signal direct.
d) Pitch shifter, pitch detune et modulateur en anneau
Le pitch shifter décale le pitch d’une valeur fixe. Cela crée un léger effet de doublage du son. Le Pitch Detune change la tonalité du pitch jusqu’à un demi ton, ce qui peut créer des dissonances.
Par le même procédé mais dans un autre état d’esprit, le Ring Modulator (ou modulateur en anneau) décale le spectre de fréquences vers le haut et vers le bas. Par exemple, si la paramètre de décalage est réglé à 100 Hz, l’entrée et toutes ses harmoniques seront décalés vers le haut de 100 Hz de manière non harmonique, c’est à dire sans coefficient entier de multiplication entre les fréquences des harmoniques d’origine et après traitement.
3. Delay
Le delay produit une répétition du signal, répété plus ou moins de fois(feed-back), chaque répétition étant plus faible que la précédente. De plus, le temps de retard (en ms) est réglable.
Il existe différents types de delays, surtout dans le domaine stéréophonique :
-
le « ping-pong » delay : le son est répété à gauche, puis à droite, puis à gauche etc.
-
le « multi tap » delay : le retard entre chaque répétition est propre au numéro de la répétition.
4. Réverbération
| Cliquez ici pour afficher l’image associée : réflexions d’une source sonore. |
La réverbération est composée d’un grand nombre d’échos distincts, appelés réflexions. Dans un espace acoustique naturel, chaque amplitude et brillance de réflexion décroissent dans le temps. Cette action de décroître est influencée par la taille de la pièce, la position de la source sonore dans la pièce, la dureté des murs, et d’autres facteurs.
Ainsi, en studio, les pièces d’enregistrement sont insonorisées et calfeutrées pour qu’il n’y ait pratiquement aucune réflexion sur les murs. Ensuite, on ajoute la réverbération pour donner l’effet voulu (souvent différent de la réverbération qui aurait été produite par la salle).
Il existe différentes réverbérations plus ou moins naturelles :
- Room : c’est une réverbération d’une pièce d’un studio moyen, assez courte.
- Hall : c’est une réverbération d’une grande pièce(salle de concert).
- A plaques (Plate) : Il s’agit des réverbérations simulées dans les années 70 à l’aide de tôles.
- Non linéaire : cette réverbération artificielle est très riche, sans amortissement du volume sonore pendant une durée T, puis coupée abruptement.

